Worum geht’s
Das Multi-Layer-Perzeptron aus dem vorigen Thema kann im Prinzip jede stetige Funktion approximieren — und scheitert trotzdem an einer scheinbar simplen Aufgabe: ein Foto zu verstehen. Der Grund ist nicht mangelnde Ausdruckskraft, sondern fehlende Struktur. Genau hier setzt dieses Kapitel an: Es geht um zwei Ideen, die zusammen das moderne Deep Learning tragen. Erstens Tiefe — viele hintereinandergeschaltete Schichten, von denen jede aus der vorigen eine abstraktere Repräsentation baut, statt dass ein Mensch die Merkmale von Hand entwirft. Zweitens das Convolutional Neural Network (CNN) — eine Netzform, die das Vorwissen „in einem Bild zählt lokale Nachbarschaft, und ein Merkmal bleibt ein Merkmal, egal wo es auftritt” direkt in die Architektur eingebaut.
Mich reizt an diesem Thema, dass das CNN kein neuer Baustein ist, sondern eine Disziplinierung des bekannten Neurons: dieselbe gewichtete Summe wie beim Perzeptron, aber mit zwei harten Sparmaßnahmen — jedes Neuron sieht nur einen kleinen Bildausschnitt, und alle Neuronen einer Karte teilen sich dieselben Gewichte. Aus dieser einen Einschränkung folgt fast alles, was CNNs so wirksam macht. Und das Herzstück, der Faltungskern, ist nichts Geheimnisvolles: ein 3×3-Kantendetektor, wie ihn die Bildverarbeitung seit Jahrzehnten von Hand benutzt — nur dass das Netz ihn jetzt selbst lernt.
Kernkonzepte
Warum vollverbundene Netze auf Bildern scheitern
Ein MLP behandelt ein Bild als langen Vektor: Schon das Foliensatz-Beispiel eines Farbbilds mit Pixeln und je drei (R,G,B)-Werten ergibt Eingabeneuronen; verbindet man sie voll mit nur verdeckten Neuronen, sind das bereits Kanten. Die Folien ziehen daraus den Schluss: Bei größeren Bildern wird das MLP unbrauchbar, weil dann Unmengen Trainingsdaten nötig wären — und es soll ja nicht die Beispielbilder speichern, sondern diskriminierende Eigenschaften extrahieren. Schwerer wiegt ein zweiter Defekt: Das MLP hat keine Translationsinvarianz. Verschiebt sich eine Katze um zehn Pixel nach rechts, trifft sie völlig andere Gewichte; das Netz müsste „Katze” an jeder Position separat lernen. Beide Probleme haben dieselbe Wurzel — das MLP weiß nicht, dass benachbarte Pixel zusammengehören und ein Muster verschiebbar ist.
Der historische Ausweg vor dem Deep Learning war Feature-Engineering: Experten legten von Hand Filtermasken zur Kantenerkennung fest (Roberts ab 1963, Prewitt, Sobel, Scharr, Kirsch). Die erreichte Datenreduktion machte Bilderkennung mit MLPs für eingeschränkte Domänen — etwa Verkehrsschilder — überhaupt praktikabel. Ein universeller, für alle Bildaufgaben tauglicher Feature-Satz ließ sich so aber nie finden, weil die Features vorab festgelegt und nicht änderbar waren.
Die Faltung: lokal und mit geteilten Gewichten
Die Antwort ist die Faltung (engl. convolution). Statt jedes Neuron mit allen Pixeln zu verbinden, gleitet ein kleiner Kernel (auch Filter) — typisch — über das Bild. An jeder Position bildet er eine lokale gewichtete Summe seines rezeptiven Felds und schreibt das Ergebnis in eine Merkmalskarte (feature map).
Zwei Sparmaßnahmen wirken hier zusammen. Die lokale Verschaltung koppelt ein Ausgabeneuron nur an sein kleines rezeptives Feld statt an das ganze Bild; die geteilten Gewichte verwenden für die gesamte Karte ein und denselben -Satz von neun Zahlen. Eine Faltungsschicht mit, sagen wir, 64 solcher Filter hat dadurch nur Parameter — unabhängig von der Bildgröße. Das ist der Kern der Aussage der Folien zur lokalen Verbundenheit (locally connected NN) mit gemeinsamen Gewichten (weight sharing): ein CNN ist ein neuronales Netz mit lokaler Verschaltung und geteilten Gewichten.
Die Folien machen die Brücke zum Neuron explizit: Eine -Filtermaske ist ein Skalarprodukt der Nachbarpixel — und genau das berechnet ein einzelnes Neuron mit Eingangskanten und der Identität als Aktivierungsfunktion. Der Faltungskern entspricht also den Eingangsgewichten dieses Neurons; am Roberts-Beispiel der Folien wird die -Maske mit den Einträgen (obere Zeile) und (untere Zeile) zu einem Neuron mit den vier Gewichten . Ordnet man jedem Pixel eine eigene Kopie dieses Neurons zu, liegt der parallele Filter als neuronale Schicht vor — und weil alle Kopien dieselben Gewichte teilen, lernt das Netz den Filter nur ein einziges Mal.
Die folgende Insel macht genau diese gleitende gewichtete Summe greifbar. Man wählt einen -Kernel und fährt über das Eingaberaster; das hervorgehobene -Empfangsfeld zeigt, aus welchen neun Pixeln das markierte Ausgabepixel berechnet wird, und die Messanzeige rechnet die Multiply-Accumulate-Summe vor.
Tipp: Wähle Sobel-x und Sobel-y nacheinander — die vertikale bzw. horizontale Kante des Bildes leuchtet jeweils auf. Ein Kernel ist nichts weiter als eine lokale gewichtete Summe, also ein Merkmalsdetektor. Der Rand wird per Zero-Padding (fehlende Nachbarn = 0) behandelt.
Sobel- lässt die vertikale, Sobel- die horizontale Kante des Testbildes aufleuchten; Laplace reagiert auf Kanten jeder Richtung, der Weichzeichner mittelt, Schärfen betont Kontraste. Es ist stets dieselbe Operation — nur die neun Kernelgewichte ändern sich.
Stride, Padding und Pooling
Drei Stellschrauben steuern, wie der Kernel das Bild abtastet. Das Padding legt einen Rand (meist Nullen) um das Bild, damit die Merkmalskarte nicht bei jeder Faltung schrumpft und Randpixel nicht benachteiligt werden. Der Stride ist die Schrittweite: Stride 1 tastet jede Position ab, Stride 2 jede zweite und halbiert so die Auflösung. Für eine Eingabegröße , Kernelgröße , Padding und Stride hat die Ausgabe die Kantenlänge
Das Pooling fasst danach für jede Merkmalskarte kleine Nachbarschaften zusammen — entweder über deren Maximum (Max-Pooling) oder Mittelwert (Mean-Pooling), typisch in einem -Fenster. Das Ergebnis ist eine Merkmalskarte geringerer Auflösung: Pooling verkleinert die Karte, dient der Datenreduktion und Abstraktion vom konkreten Bildbeispiel und schenkt dem Netz eine begrenzte Toleranz gegen kleine Verschiebungen — ob das Merkmal exakt links oder einen Pixel weiter rechts feuerte, ist danach gleichgültig. Filtergröße, Padding, Stride und Pooling zählen laut Folien zu den zentralen Hyperparametern, die ein CNN über die übliche Netzarchitektur hinaus zu konfigurieren hat.
Architektur und Merkmalshierarchie
Ein typisches CNN stapelt diese Bausteine: Conv → ReLU → Pool, mehrfach wiederholt, und am Ende einige vollverbundene Schichten (in den Folien Detection Head genannt) für die Klassifikation Bild → Label (so etwa die klassischen Netze LeNet, AlexNet, VGG16, ResNet). Die ReLU-Stufe ist dabei keine eigene Schicht, sondern einfach die ReLU-Aktivierungsfunktion der Faltungsneuronen; ihr Aktivierungsgrad lässt sich lesen als das Maß, zu dem das in der Filtermaske codierte Merkmal (z.B. eine Kante) an dieser Bildstelle „gesehen” wurde. Entscheidend ist, was in diesem Stapel emergiert: eine Merkmalshierarchie. Wie die Folien sie beschreiben, lernt das Modell zunächst Pixel unterschiedlicher Helligkeit, kombiniert sie zu Kanten und einfachen Formen, daraus zu komplexeren Objekten und schließlich etwa dazu, aus welchen Teilen sich ein Gesicht zusammensetzt. Niemand programmiert diese Stufen — sie ergeben sich aus dem Training. Genau das meint Repräsentationslernen: Die Tiefe des Netzes ist die Tiefe der Abstraktion.
Woher kommen diese Filter? Die Folien zeigen einen eleganten Weg, sie ohne Labels aus den Daten zu gewinnen: einen Autoencoder. Stellt man eine Filtermaske als Neuron dar, lässt sich ein Auto-Encoder-Netz bauen, das aus zufällig gezogenen Bild-Stichproben genau die Filter lernt, mit denen sich die Bilder möglichst gut wieder rekonstruieren lassen. Anschließend trennt man den Decoder ab und schaltet den so vortrainierten Encoder einem Klassifikator (MLP oder SVM) vor. In der Praxis ist dieses zweistufige Vorgehen heute seltener — meist trainiert man das gesamte Klassifikations-CNN „in einem Aufwasch” durch. Über die reine Klassifikation hinaus erkennt YOLO (You Only Look Once) Objekte samt Position in Echtzeit in einem einzigen Durchlauf, und der Vision Transformer (ViT) zerschneidet das Bild in Kacheln und ersetzt die Faltung durch Aufmerksamkeit über diese — die Brücke zu Thema 7.3.
Praxis
Um zu zeigen, dass an einer Faltungsschicht wirklich nichts Magisches ist, habe ich
das Vorlesungsbild Forstweg.jpg in reinem NumPy von Hand gefaltet — ohne
scipy.signal, nur mit numpy-Verschiebungen. Drei klassische Kanten-Kerne kommen
zum Einsatz; die Kantenbilder reproduzieren die Vorlesungsdateien
Forstweg_VKanten.gif und Forstweg_HKanten.gif.
Die Faltung selbst ist eine vektorisierte Variante der Summe aus der Definition oben: Statt für jedes Pixel neun Produkte einzeln zu bilden, verschiebe ich das ganze (randfortgesetzte) Bild neunmal und gewichte es mit dem jeweiligen Kernel-Eintrag.
SOBEL_X = np.array([[-1, 0, 1], [-2, 0, 2], [-1, 0, 1]], dtype=float)
SOBEL_Y = np.array([[-1, -2, -1], [0, 0, 0], [1, 2, 1]], dtype=float)
LAPLACE = np.array([[0, 1, 0], [1, -4, 1], [0, 1, 0]], dtype=float)
def convolve2d(image, kernel):
kh, kw = kernel.shape
ph, pw = kh // 2, kw // 2
padded = np.pad(image, ((ph, ph), (pw, pw)), mode="edge")
out = np.zeros_like(image, dtype=float)
for i in range(kh):
for j in range(kw):
out += kernel[i, j] * padded[i:i + image.shape[0], j:j + image.shape[1]]
return outDas vollständige Skript (Laden des Bildes via matplotlib.image.imread,
Graustufenwandlung nach Rec. 709, die drei Faltungen, Abbildungen als PNG) liegt in
python/src/eport_figures/praxis/p_7_2_cnn.py. Seine Ausgabe:
Bild: Forstweg.jpg (500x355 px, Graustufen 0..1)
Sobel-x (vert. Kanten) Antwort in [-1.98, +1.89], mittl. Betrag 0.163
Sobel-y (horiz. Kanten) Antwort in [-2.06, +2.23], mittl. Betrag 0.198
Laplace (isotrop) Antwort in [-0.33, +0.31], mittl. Betrag 0.020
Gradientenbetrag |G| Antwort in [+0.00, +2.33], mittl. Betrag 0.287
Kantenenergie vertikal/horizontal = 0.82 (mehr horizontale Struktur)
geschrieben: forstweg_kanten.png, forstweg_kernels.png
Original und die beiden Sobel-Antworten (über den Betrag, invertiert
dargestellt: dunkel = starke Kante). Sobel- misst den horizontalen
Helligkeitsgradienten und hebt damit vertikale Strukturen hervor — den
Schildpfosten und die Schildkanten, ganz wie Forstweg_VKanten.gif. Sobel-
betont umgekehrt die horizontalen Linien, vor allem den Wegrand,
entsprechend Forstweg_HKanten.gif.
Die Sobel-- und Sobel--Karten teilen ihre Kantenenergie im Verhältnis 0.82 auf — im Forstweg-Motiv steckt etwas mehr horizontale Struktur (der breite Wegverlauf) als vertikale. Der Laplace-Operator, die diskrete zweite Ableitung, reagiert isotrop auf Kanten jeder Richtung; der Gradientenbetrag fasst beide Sobel-Richtungen zu einer richtungsunabhängigen Kantenstärke zusammen.
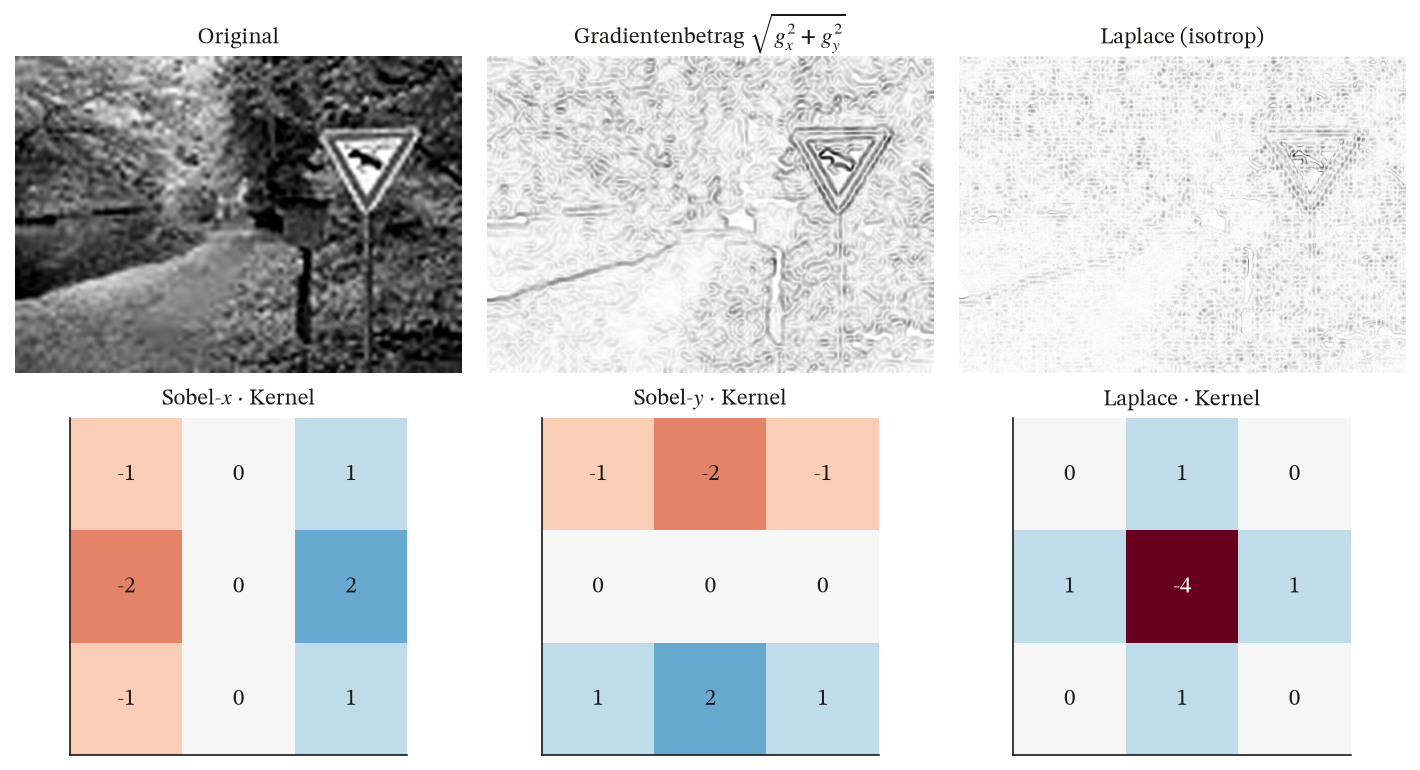
Oben die richtungsunabhängigen Antworten (Gradientenbetrag, Laplace), unten die drei verantwortlichen -Kerne als Zahlenmatrix (blau negativ, rot positiv). Jeder Kern ist nur neun von Hand gewählte Zahlen.
Der entscheidende Punkt: Diese drei Kerne sind fest vorgegebene Kantendetektoren aus dem Lehrbuch der Bildverarbeitung. Eine Faltungsschicht im CNN hat exakt dieselbe Form — neun Gewichte, die über das ganze Bild geteilt werden — nur dass sie diese Zahlen nicht aus einem Lehrbuch bezieht, sondern sie per Backpropagation selbst lernt. Visualisiert man die erste Schicht eines trainierten CNN, findet man genau solche Kanten- und Farbfilter wieder. Ein Kernel ist ein lernbarer Kantendetektor — das ist die Brücke zwischen klassischer Signalverarbeitung und gelerntem Sehen.
Querbezüge
- 7.1 (Neuronale Netze): Das CNN ist kein neuer Baustein, sondern ein MLP unter zwei Auflagen — lokale rezeptive Felder und geteilte Gewichte. Jedes Faltungsneuron bildet dieselbe gewichtete Summe wie das Perzeptron, nur dass der -Kernel ist und für die ganze Karte derselbe. Trainiert wird ebenfalls mit Backpropagation; die Kettenregel läuft nur zusätzlich über die geteilten Gewichte.
- 7.3 (Transformer / Attention): Der Vision Transformer ersetzt das fest lokale rezeptive Feld der Faltung durch gelernte Aufmerksamkeit, die im Prinzip jede Bildkachel mit jeder anderen koppeln kann — globaler, aber datenhungriger. CNN und ViT sind zwei Antworten auf dieselbe Frage: Welches Vorwissen über Bilder baut man in die Architektur ein?
- Bild- und Signalverarbeitung: Die diskrete Faltung, Sobel-, Laplace- und Gauß-Filter stammen direkt aus der klassischen Signalverarbeitung; ein CNN übernimmt diese Operation und macht ihre Koeffizienten lernbar. Pooling ist eine Form des Downsamplings, der Gradientenbetrag der bekannte Kantenoperator.
- Lineare Algebra: Jede Faltung lässt sich als (sehr dünn besetzte, durch das Teilen der Gewichte stark gebundene) Matrix-Vektor-Multiplikation schreiben — das Weight-Sharing ist nichts anderes als eine Toeplitz-artige Bandstruktur dieser Matrix. Der Gradientenbetrag ist die euklidische Norm des Gradientenvektors.
- Analysis / Numerik: Sobel approximiert die erste, Laplace die zweite Ableitung des Helligkeitsbildes über finite Differenzen — Kanten sind die Extrema des Gradienten bzw. die Nulldurchgänge des Laplace.
Quellen
- Foliensätze
_710_DL_DNN.pdf(Deep Learning / DNN) und_720_DL_CNN.pdf(Bildanalyse mit CNN) — Grundlage für die Begriffe Faltung, Pooling, Stride/Padding und die Conv-Pool-FC-Architektur. Die Folien motivieren das CNN über das Parameterproblem des MLP; diese Argumentationslinie habe ich übernommen, aber mit eigenen Zahlenbeispielen unterlegt. - Vorlesungsbild
Forstweg.jpgsamt der KantenbilderForstweg_VKanten.gifundForstweg_HKanten.gif— als Zielvorgabe für die Praxis: Mein handgefalteter Sobel sollte dieselben vertikalen/horizontalen Kanten liefern, was er tut. - Russell & Norvig, Artificial Intelligence: A Modern Approach, Kapitel zu Deep Learning — konsultiert für die saubere Trennung von lokaler Verschaltung, geteilten Gewichten und der daraus folgenden Translationsäquivarianz.
- ConvNetJS — im Browser ausprobiert, um die emergierende Merkmalshierarchie (Kanten → Texturen → Objekte) an einem live trainierten CNN zu sehen; das hat die obige Insel inspiriert.
- Zeiler & Fergus, Visualizing and Understanding Convolutional Networks (arXiv 1311.2901) (in den Folien als 2013 zitiert, publiziert ECCV 2014) — für die Beobachtung, dass die ersten gelernten Filter tatsächlich Kantendetektoren sind, also genau die Sobel-artigen Kerne aus der Praxis.